索引优化(二)
# 1、Join语句的优化
[神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(一)](https://www.jianshu.com/p/d7e5fde4417e)
[神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(二)](https://www.cnblogs.com/youzhibing/p/12012952.html)
[SQL 之 ON 和 WHERE执行顺序](https://www.jianshu.com/p/73c3088e39fa)
**Join 性能点**
当我们执行两个表的Join的时候,就会有一个比较的过程,逐条比较两个表的语句是比较慢的,因此可以把两个表中数据依次读进一个内存块中,在Mysql中执行:show variables like 'join_buffer_size',可以看到join在内存中的缓存池大小,其大小将会影响join语句的性能。
在执行join的时候,数据库会选择一个表把他**要返回以及需要进行和其他表进行比较的数据**放进join_buffer(如下)。
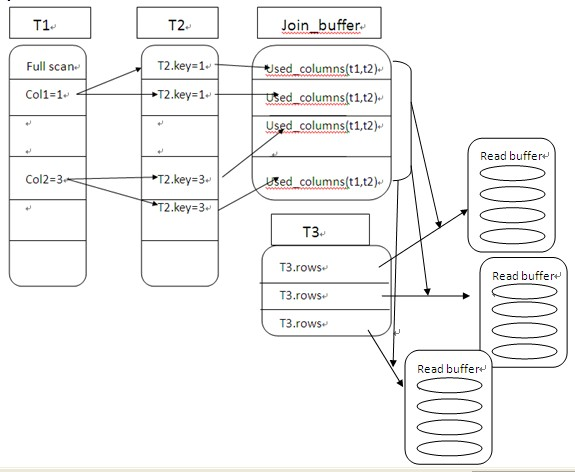
如果是有索引的情况,则直接读取两个表的索引树进行比较就可以了。
若没有索引,则会使用 'Block nested loop' 算法,Block 块,也就是说每次都会取一块数据到内存以减少I/O的开销
所以实践中,尽可能减少Join语句中的NestedLoop的循环次数:“永远用小结果集驱动大的结果集”
1. **用小结果集驱动大结果集**,将筛选结果小的表首先连接,再去连接结果集比较大的表,尽量减少join语句中的Nested Loop的循环总次数
2. **优先优化Nested Loop的内层循环**(也就是最外层的Join连接),因为内层循环是循环中执行次数最多的,每次循环提升很小的性能都能在整个循环中提升很大的性能;
3. 对被驱动表的join字段上**建立索引**;
4. 当被驱动表的join字段上无法建立索引的时候,**设置足够的Join Buffer Size**。
5. **尽量用inner join**(因为其会自动选择小表去驱动大表).避免 LEFT JOIN (一般我们使用Left Join的场景是大表驱动小表)和NULL,那么如何优化Left Join呢?
- **条件中尽量能够过滤一些行将驱动表变得小一点,用小表去驱动大表**
- 右表的条件列一定要加上索引(主键、唯一索引、前缀索引等),最好能够使type达到range及以上(ref,eq_ref,const,system)
6. 适当地在表里面添加冗余信息来减少join的次数
7. 使用更快的固态硬盘
性能优化,left join 是由左边决定的,左边一定都有,所以右边是我们的关键点,建立索引要建在右边。当然如果索引是在左边的,我们可以考虑使用右连接,如下
```sql
select * from atable
left join btable on atable.aid=btable.bid; //最好在bid上建索引
```
(Tips:Join左连接在右边建立索引;组合索引则尽量将数据量大的放在左边,在左边建立索引)
----
# 2、避免索引失效
**1.[最左前缀原则](https://blog.csdn.net/wx145/article/details/82839419)**
如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始并且不跳过索引中的列。Mysql查询优化器会对查询的字段进行改进,判断查询的字段以哪种形式组合能使得查询更快,所有比如创建的是(a,b)索引,查询的是(b,a),查询优化器会修改成(a,b)后使用索引查询。
**2.不在索引列上做任何操作**
(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描。
**3.存储引擎不能使用索引中范围条件右边的列**
如这样的sql语句:
```sql
select * from user where username='123' and age>20 and phone='1390012345'
```
其中username, age, phone都有索引,但只有username和age会生效,phone的索引没有用到。
**4.尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致))**
尽量使用如 select age from user
减少使用如 select *
因为覆盖索引:SQL只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。
**5.mysql在使用不等于(!= 或者 <>)的时候无法使用索引会导致全表扫描**
**6.is null, is not null 也无法使用索引,在实际中尽量不要使用null**
不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列这样的情况下,只要这些列中有一列含有null,该列 就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。 任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
**7.like 以通配符开头(‘%abc..’)mysql索引失效会变成全表扫描的操作**
所以最好用右边like 'abc%'。如果两边都要用,可以用
```sql
select age from user where username like '%abc%'
```
其中age是必须是索引列,才可让索引生效
假如index(a,b,c), where a=3 and b like 'abc%' and c=4,则a能用,b能用,c不能用,类似于不能使用范围条件右边的列的索引
对于一棵B+树来讲,如果根是字符def,如果通配符在后面,例如abc%,则应该搜索左面,例如efg%,则应该搜索右面,如果通配符在前面%abc,则不知道应该走哪一面,还是都扫描一遍吧。
**8.字符串不加单引号索引失效**
**9.尽量避免子查询,而用join**
**10、在组合索引中,将有区分度的索引放在前面**
如果没有区分度,例如用性别,相当于把整个大表分成两部分,查找数据还是需要遍历半个表才能找到,使得索引失去了意义。
**11、避免在 where 子句中对字段进行 null 值判断**
对于null的判断会导致引擎放弃使用索引而进行全表扫描。
**必看:** [索引失效原理,终于有人讲明白了](https://cloud.tencent.com/developer/article/1704743)
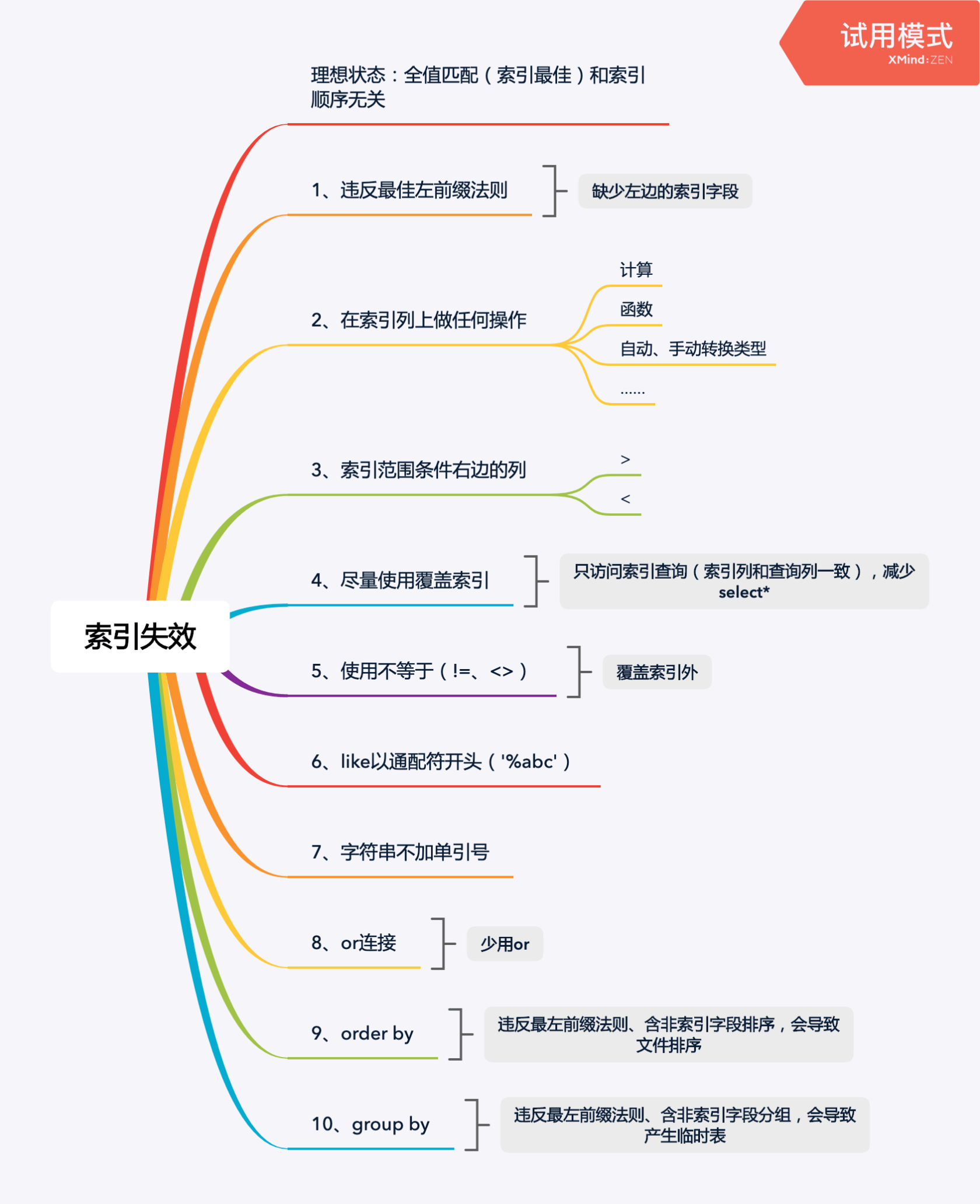
图片来自:[一张图搞懂MySQL的索引失效](https://segmentfault.com/a/1190000021464570)
----
# 3、索引创建规则:
- 表的主键、外键必须有索引;
- 数据量超过300的表应该有索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引;
- 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
- 索引应该建在选择性高的字段上;
- 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
- 复合索引的建立需要进行仔细分析,尽量考虑用单字段索引代替;
- 正确选择复合索引中的主列字段,一般是选择性较好的字段;
- 复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
- 如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
- 如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
- 如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
- 频繁进行数据操作的表,不要建立太多的索引;
- 删除无用的索引,避免对执行计划造成负面影响;
- 表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。
- 尽量不要对数据库中某个含有大量重复的值的字段建立索引。
---
# 4、慎用索引
4.1 应尽可能的避免更新 clustered 索引数据列, 因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
34.2 索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。