Hive 内置函数(一)
# 一、引言
不同于普通的SQL函数,Hive支持一些其他sql不支持的函数,如表生成函数和窗口函数,集合函数等等,接下来对应一一解答。
# 二、表生成函数
## 2.1 列转行(collect_list/collect_set)
Hive中collect相关的函数有collect_list和collect_set。
它们都是将分组中的**某列转为一个数组返回**,**不同的是collect_list不去重而collect_set去重。**
做简单的实验加深理解,创建一张实验用表,存放用户每天点播视频的记录:
```sql
create table t_visit_video (
username string,
video_name string
) partitioned by (day string)
row format delimited fields terminated by ',';
```
在本地文件系统创建测试数据文件:
```language
张三,大唐双龙传
李四,天下无贼
张三,神探狄仁杰
李四,霸王别姬
李四,霸王别姬
王五,机器人总动员
王五,放牛班的春天
王五,盗梦空间
```
将数据加载到Hive表:
`load data local inpath '/root/hive/visit.data' into table t_visit_video partition (day='20180516');`
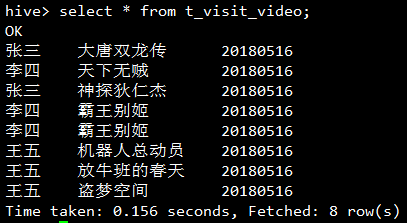
按用户分组,取出每个用户每天看过的所有视频的名字:
```sql
select username, collect_list(video_name) from t_visit_video group by username ;
```

但是上面的查询结果有点问题,因为霸王别姬实在太好看了,所以李四这家伙看了两遍,这直接就导致得到的观看过视频列表有重复的,所以应该增加去重,使用collect_set,其与collect_list的区别就是会去重:
```sql
select username, collect_set(video_name) from t_visit_video group by username;
```

李四的观看记录中霸王别姬只出现了一次,实现了去重效果。
**突破group by限制**
还可以利用collect来突破group by的限制,Hive中在group by查询的时候要求出现在select后面的列都必须是出现在group by后面的,即select列必须是作为分组依据的列,但是有的时候我们想根据A进行分组然后随便取出每个分组中的一个B,代入到这个实验中就是按照用户进行分组,然后随便拿出一个他看过的视频名称即可:
```sql
select username, collect_list(video_name)[0] from t_visit_video group by username;
```

video_name不是分组列,依然能够取出这列中的数据。
## 2.2 行转列函数(explode/posexplode)
explode:可以将集合的数据遍历出来,遍历出的每一个元素为新的一行。注意,使用explode会生成一个新的表:
**如下示例:**
```sql
select * from t_stu_subject;
+-------------------+---------------------+-----------------------------+--+
| t_stu_subject.id | t_stu_subject.name | t_stu_subject.subjects |
+-------------------+---------------------+-----------------------------+--+
| 1 | zhangsan | ["化学","物理","数学","语文"] |
| 2 | lisi | ["化学","数学","生物","生理","卫生"] |
| 3 | wangwu | ["化学","语文","英语","体育","生物"] |
+-------------------+---------------------+-----------------------------+--+
3 rows selected (0.176 seconds)
-->对subjects字段进行行转列
select explode(subjects) from t_stu_subject;
+------+--+
| col |
+------+--+
| 化学 |
| 物理 |
| 数学 |
| 语文 |
| 化学 |
| 数学 |
| 生物 |
| 生理 |
| 卫生 |
| 化学 |
| 语文 |
| 英语 |
| 体育 |
| 生物 |
+------+--+
-->错误语句:explode生成的是一个表,所以下面会报错
select id,name,explode(subjects) from t_stu_subject;
Error: Error while compiling statement: FAILED: SemanticException [Error 10081]: UDTF's are not supported outside the SELECT clause, nor nested in expressions (state=42000,code=10081)
```
**posexplode** 相比在explode之上,将一列数据转为多行之后,还会输出数据的下标(如下图的t.pos)。

注:explode函数也可以对map类型使用:
```sql
hive> select explode(array('A','B','C'));
OK
A
B
C
Time taken: 4.879 seconds, Fetched: 3 row(s)
hive> select explode(map('A',10,'B',20,'C',30));
OK
A 10
B 20
C 30
Time taken: 0.261 seconds, Fetched: 3 row(s)
```
## 2.3 表生成函数(lateral view explode)
lateral view用于和split、explode等UDTF一起使用的,能将一行数据拆分成多行数据,在此基础上可以对拆分的数据进行聚合,lateral view首先为原始表的每行调用UDTF,UDTF会把一行拆分成一行或者多行,lateral view在把结果组合,产生一个支持别名表的虚拟表。
上面的explode使用看起来毫无意义,但是我们可以结合lateral view来一起使用,如下:
```sql
select id,name,sub from t_stu_subject lateral view explode(subjects) tmp as sub;
+-----+-----------+------+--+
| id | name | sub |
+-----+-----------+------+--+
| 1 | zhangsan | 化学 |
| 1 | zhangsan | 物理 |
| 1 | zhangsan | 数学 |
| 1 | zhangsan | 语文 |
| 2 | lisi | 化学 |
| 2 | lisi | 数学 |
| 2 | lisi | 生物 |
| 2 | lisi | 生理 |
| 2 | lisi | 卫生 |
| 3 | wangwu | 化学 |
| 3 | wangwu | 语文 |
| 3 | wangwu | 英语 |
| 3 | wangwu | 体育 |
| 3 | wangwu | 生物 |
+-----+-----------+------+--+
```
**SQL代码解析:**
> **理解**: lateral view 相当于两个表在join
**左表**:是原表
**右表**:是explode(某个集合字段)之后产生的表
**而且**:这个join只在同一行的数据间进行
**实例二:求word count**
```sql
实例一: ==== 利用explode和lateral view 实现hive版的wordcount
有以下数据:
a b c d e f g
a b c
e f g a
b c d b
对数据建表:
create table t_juzi(line string) row format delimited;
导入数据:
load data local inpath '/root/words.txt' into table t_juzi;
** ***** ******** ***** ******** ***** ******** wordcount查询语句:***** ******** ***** ******** ***** ********
select a.word,count(1) cnt
from
(select tmp.* from t_juzi lateral view explode(split(line,' ')) tmp as word) a
group by a.word
order by cnt desc;
+---------+------+--+
| a.word | cnt |
+---------+------+--+
| b | 4 |
| c | 3 |
| a | 3 |
| g | 2 |
| f | 2 |
| e | 2 |
| d | 2 |
+---------+------+--+
```
# 三、集合函数
## 3.1 判断值是否存在某集合(array_contains)
**array_contains:语法结构**
> array_contains(Array<T>, value) 返回boolean值
**示例:**
```sql
-->源数据查看
select * from t_stu_subject;
+-------------------+---------------------+-----------------------------+--+
| t_stu_subject.id | t_stu_subject.name | t_stu_subject.subjects |
+-------------------+---------------------+-----------------------------+--+
| 1 | zhangsan | ["化学","物理","数学","语文"] |
| 2 | lisi | ["化学","数学","生物","生理","卫生"] |
| 3 | wangwu | ["化学","语文","英语","体育","生物"] |
+-------------------+---------------------+-----------------------------+--+
3 rows selected (0.066 seconds)
-->array_contains使用
select id, name, array_contains(subjects, '语文') from t_stu_subject;
+-----+-----------+--------+--+
| id | name | _c2 |
+-----+-----------+--------+--+
| 1 | zhangsan | true |
| 2 | lisi | false |
| 3 | wangwu | true |
+-----+-----------+--------+--+
3 rows selected (13.573 seconds)
```
## 3.2 集合排序(sort_array)
**sort_array:语法结构**
> sort_array(Array<T>) 返回排序后的数组
**示例:**
```sql
select sort_array(array(3,2,6));
+----------+--+
| _c0 |
+----------+--+
| [2,3,6] |
+----------+--+
1 row selected (12.599 seconds)
```
## 3.3 集合长度(size)
```sql
-->数据查询
select * from t_stu_subject;
+-------------------+---------------------+-----------------------------+--+
| t_stu_subject.id | t_stu_subject.name | t_stu_subject.subjects |
+-------------------+---------------------+-----------------------------+--+
| 1 | zhangsan | ["化学","物理","数学","语文"] |
| 2 | lisi | ["化学","数学","生物","生理","卫生"] |
| 3 | wangwu | ["化学","语文","英语","体育","生物"] |
+-------------------+---------------------+-----------------------------+--+
3 rows selected (0.069 seconds)
-->size测试
select id, name, size(subjects) as sub_num from t_stu_subject;
+-----+-----------+----------+--+
| id | name | sub_num |
+-----+-----------+----------+--+
| 1 | zhangsan | 4 |
| 2 | lisi | 5 |
| 3 | wangwu | 5 |
+-----+-----------+----------+--+
3 rows selected (13.578 seconds)
```
## 3.4 Map集合的keys值返回
**语法格式:**
> map_keys(Map<T,T>)
**实例:**
```sql
select * from t_family;
+--------------+----------------+----------------------------------------------------------------+---------------+--+
| t_family.id | t_family.name | t_family.family_members | t_family.age |
+--------------+----------------+----------------------------------------------------------------+---------------+--+
| 1 | zhangsan | {"father":"xiaoming","mother":"xiaohuang","brother":"xiaoxu"} | 28 |
| 2 | lisi | {"father":"mayun","mother":"huangyi","brother":"guanyu"} | 22 |
| 3 | wangwu | {"father":"wangjianlin","mother":"ruhua","sister":"jingtian"} | 29 |
| 4 | mayun | {"father":"mayongzhen","mother":"angelababy"} | 26 |
+--------------+----------------+----------------------------------------------------------------+---------------+--+
-- 查出每个人有哪些亲属关系
select id,name,map_keys(family_members) as relations,age
from t_family;
+-----+-----------+--------------------------------+------+--+
| id | name | relations | age |
+-----+-----------+--------------------------------+------+--+
| 1 | zhangsan | ["father","mother","brother"] | 28 |
| 2 | lisi | ["father","mother","brother"] | 22 |
| 3 | wangwu | ["father","mother","sister"] | 29 |
| 4 | mayun | ["father","mother"] | 26 |
+-----+-----------+--------------------------------+------+--+
4 rows selected (0.129 seconds)
```
## 3.5 Map集合的values值返回
**语法结构:**
>map_values(Map<T,T>)
**实例:**
```sql
-- 查出每个人的亲人名字
select id,name,map_values(family_members) as relations,age
from t_family;
+-----+-----------+-------------------------------------+------+--+
| id | name | relations | age |
+-----+-----------+-------------------------------------+------+--+
| 1 | zhangsan | ["xiaoming","xiaohuang","xiaoxu"] | 28 |
| 2 | lisi | ["mayun","huangyi","guanyu"] | 22 |
| 3 | wangwu | ["wangjianlin","ruhua","jingtian"] | 29 |
| 4 | mayun | ["mayongzhen","angelababy"] | 26 |
+-----+-----------+-------------------------------------+------+--+
4 rows selected (0.132 seconds)
```
# 四、Json解析函数
- hive中内置了json解析函数,但是只能解析单层的json对象,对于比较复杂的json,还是需要自己写UDF进行解析。
## 4.1 get_json_object
**作用**:解析json字符串对象,通过 '$.key' 来获取json串的value值
**语法格式:**
>get_json_object(json字符串,'$.key')
**实例:**
```sql
select get_json_object('{"key1":3333, "key2": 4444}', '$.key1');
+-------+--+
| _c0 |
+-------+--+
| 3333 |
+-------+--+
```
详细:[Hive】解析json(get_json_object)](https://blog.csdn.net/qq_34105362/article/details/80454697)
## 4.2 json_tuple
**作用**:将json字符串的value值进行提取
**语法格式:**
>json_tuple(json字符串,key值1,key值2) as (key1, key2)
**实例:**
```sql
select json_tuple('{"key1":3333, "key2": 4444}', 'key1', 'key2') as (key1, key2);
+-------+-------+--+
| key1 | key2 |
+-------+-------+--+
| 3333 | 4444 |
+-------+-------+--+
```
更多:[Hive处理Json的几个函数](https://www.yuque.com/cuteximi/base/fyhzo3)
---
参考:
[Hive 学习(七) Hive之常用内置函数二](https://www.cnblogs.com/tashanzhishi/p/10904144.html)
[Hive笔记之collect_list/collect_set(列转行)](https://www.cnblogs.com/cc11001100/p/9043946.html)