笔记
**关于MapReduce原理与key/value由来见:[MapReduce原理](https://github.com/sunnyandgood/BigData/blob/master/MapReduce/MapReduce%E5%8E%9F%E7%90%86.md) + [Hadoop MapReduce原理及实例](https://blog.csdn.net/u010758410/article/details/79795041)**
# 1、<font color=red>**MAP/REDUCE操作的key/value如何确定?**</font>
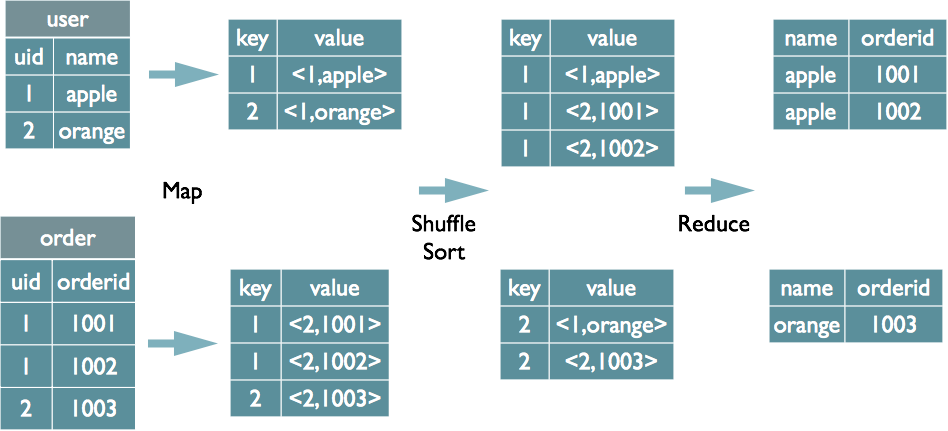
**1. 对于 JOIN 操作:**
- **Map:**
以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
以 JOIN 之后所关心的列作为 Value,当有多个列时,Value 是这些列的组合。在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表。
按照 Key 进行排序。
- **Shuffle:**
根据 Key 的值进行 Hash,并将 Key/Value 对按照 **Hash** 值推至不同对 Reduce 中。
- **Reduce:**
Reducer 根据 Key 值进行 Join 操作,并且通过 Tag 来识别不同的表中的数据。
例如:`select u.name, o.orderid from order o join user u on o.uid = u.uid;`
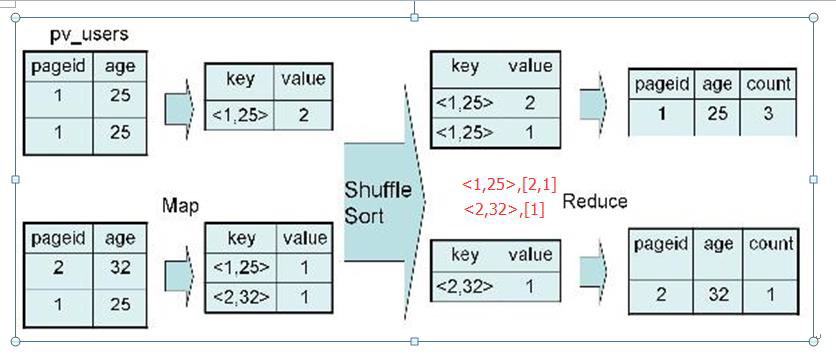
**2. 对于Group by操作:**
- **Map:**
以 Group by条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
根据key值聚合
按照 Key 进行排序。
- **Shuffle:**
根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推至不同对 Reduce 中。
- **Reduce:**
Reducer 根据 Key 值进行 聚合 操作。
例如:`SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age; `
**3. Distinct**
按照 age 分组,然后统计每个分组里面的不重复的 pageid 有多少个
`SELECT age, count(distinct pageid) FROM pv_users GROUP BY age;`
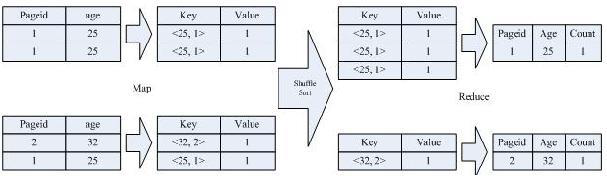
>此时,将数据源的VALUE作为key输出,VALUE随意
<font color=#008000>**3. 对于其他操作**</font>
暂无
来源:[HIVE 的MAP/REDUCE](https://www.shuzhiduo.com/A/VGzlYZpVJb/)
---
关于:[面试官最爱问的「Hive调优」,17个切入点带你一举拿下](https://mp.weixin.qq.com/s?__biz=MzUzODYwMDAzNA==&mid=2247504808&idx=3&sn=1643567f6ff0fd1d1fdc20cfac4ce44e&chksm=fad7a4a5cda02db33094b514ece7ce605c5286132552d8f37183c96ae2ee2d54dbd09f711200&mpshare=1&scene=23&srcid=1102bELgOfBL4EeWnI2XyMeS&sharer_sharetime=1604712251481&sharer_shareid=e7aab36d78b279ccf29394736ce26e0f#rd)中第四点 **++怎样做笛卡尔积++**,举例为:
> 另一种解决方案是: **额外构造join key (连接键)**,通过表连接操作代替笛卡尔积 操作,具体做法是将小表扩充一列join key,并将小表的条目复制数倍,且join key各不相 同;将大表扩充一列join key为小表扩充数倍之后数据总量范围内的随机数。例如,假设小 表中只有1条数据,大表中1000条数据,给小表添加一列join key,设其值为1,将该数据扩 充四倍,其join key的值分别为2〜5,大表中的join key,使用1〜5之间的随机数,比如有 200个1,200个2,200个3,200个4和200个5,此时,根据join key进行两个表的连接操作时, 就会产生5个reducer,同时将大表的数据随机分成了5份(小表扩展后的倍数),从而解决了 上述问题。但是,该解决方案的的本质仍然与笛卡尔积操作相同,其弊端是会造成数据的冗 余,且实际执行起来比较繁琐、效率低下。
---
# 2、[Hive设置map和reduce的个数](https://blog.csdn.net/B11050101/article/details/78754652)
# 3、[Hive学习之抽样(tablesample)](https://blog.csdn.net/leen0304/article/details/78961941)