承影映射器
# 承影映射器 v0.5
## (一)、诞生缘由
创星编译器的最终目的,是为了实现创星集团产品前后端开发的无代码化。让公司从“微服务”走向“中台化”的过程更加顺畅,真正的实现“中台之后无代码”。
但在编译的过程中,存在服务与服务之间出入参对接与调度的难点:
- 1. 技术难点: 有模板时的服务出入参接口匹配与无模板时服务出入参的接口匹配;
- 2. 业务难点:业务使用过程中会因为某些字段的差异性导致无法精准匹配,需要一套智能解析的算法实现。
因此,我们打造了创星映射器这一内核技术平台,用来智能匹配服务与服务出入参之间的接口对接与调度。
## (二)、实现效果
全面提升了开发效率,最坏情况提高倍,最好情况提高倍。
全面改善产品质量和运行效率,最坏情况提速10%,最好情况提速1000%以上。
帮助推进创新中台在公司内部的推广和使用,为中台提供核心竞争力。
创星映射器当前可以实现全方位的数据类型间映射,我们在应对数据类型对接的时候,自定义了一款基于JSON格式名为TGDL(创星通用描述性语言)的中间体语言
## (三)、实现困难
在做智能匹配时,数据集样本的不足,导致相似度无法完整的按照深度学习模型去计算,但当前可采取一些简单的阈值回归得到近似值。
计划任务:
实现完全自动mapping
优化代码结构,增强代码可读性
全自动/半自动生成服务的单元测试
## (四)、未来方向
- 1.承影0.5版本(流程建模阶段):有简单的前后端开发功能,直接生成代码
- 2.承影1.0版本(流程建模阶段):加入项目的概念,将前后端打通
- 3.承影1.5版本时:进行扩张尝试,与纯均, 鱼肠整合,在承影流程设计器中引入规则建模
- 4.承影2.0版本时:进行全面扩张,在承影流程设计器中再引入数据建模、权限建模
- 5.承影2.5版本时:化繁为简,全面进行整合,将承影设计器全面融合到全开发环节可视化建模中
层级关系:承影设计器-流程建模-映射器
## (五)、架构简图
## (六)、核心代码实现案例
- 1. 出入参的模板
```python
#入参模板
argument_template = {
"type": "Argument",
"value": {
"type": "Normal",
"serviceNodeId": "",
"serviceKeyName": ""
}
}
#出参模板
result_template = {
"type": "Result",
"value": {
"type": "Normal",
"serviceNodeId": "",
"serviceKeyName": ""
}
}
#map类型模板
map_template = {"type": "Map", "value": {}}
#列表类型模板
list_template = {"type": "List", "value": []}
```
- 2. 结点数据的哈希化
```python
async def take_node_hash(node: Union[mapping_query.QueryNode, mapping_entity.Node]) -> int:
#当结点类型为入口(Entry)时,对结点的值进行哈希化
if node.type == mapping_entity.NodeType.Entry:
return hash(node.type)
#当结点类型为服务(Service)时,对结点属性的服务(service) ID和接口(api) ID两个值进行哈希化
elif node.type == mapping_entity.NodeType.Service:
return hash(node.properties.service.id + "-" + node.properties.api.id)
#当结点类型为SQL时,对结点的SQL语句进行哈希化
elif node.type == mapping_entity.NodeType.SQL:
return hash(node.properties.command)
```
- 3. 是否需要智能解析的判定
```Python
#服务结点间的映射函数实现
async def get_service_mapping(
from_nodes: List[mapping_query.QueryNode], to_node: mapping_query.QueryNode
) -> Dict[str, Any]:
# 判断是否需要智能解析
###结点为SQL类型时获取服务(service_name)和接口(interface_name)对应的SQL语句
if to_node.type is NodeType.SQL:
repo = await repository_lib.get_registered_sql_service()
doc = repo["index"].get(to_node.properties.command, None)
###结点为服务类型时获取服务的服务ID和接口ID
elif to_node.type is NodeType.Service:
repo = await repository_lib.get_registered_service()
doc = repo.get(to_node.properties.service.id, {}).get(to_node.properties.api.id, None)
# 如果没有找到模版,执行智能解析
if doc is None:
return {"Guess": True, "Arguments": await guess_service_mapping(from_nodes, to_node)}
# 遍历模板里的mapping映射内容
for mapping in doc.Mappings:
depends = mapping.depends
requires: Dict[int, str] = {await take_node_hash(v): k for k, v in depends.items()}
provides: Dict[int, mapping_query.QueryNode] = {await take_node_hash(x): x for x in from_nodes}
#取哈希化后的结点组成一个集合
difference = set(requires.keys()).difference(set(provides.keys()))
print(requires, provides)
#如果结果为空,则将JSON模板转为python对象并返回
if not difference:
template = Template(json.dumps(mapping.template))
template_mapping = {}
for h in requires:
template_mapping[requires[h]] = provides[h].id
return {"Guess": "False", "Arguments": json.loads(template.substitute(template_mapping))}
#如果有结果,则返回找不到匹配的映射
raise RuntimeException("找不到匹配的映射")
```
- 4. 获取JSON格式文档数据的路径
```Python
async def construct_result(path: List[str], argument: Dict, res: Any):
# 当 path 为空时,停止递归
if not path:
return
# 若 path 不为空,则进行递归
elif len(path) >= 1:
#删除路径里的第一个元素
curr_path = path.pop(0)
# res[0]["Value"]["Code"] res["0"]["Value"]["Code"]
# res "0:Int/Value/Code"
# 0,
#如果当前路径里包含了:且数据类型为int时
if ":" in curr_path and curr_path.split(":")[1].lower().startswith("int"):
curr_path = int(curr_path.split(":")[0])
# TGDL: {"type":"Nothing"} -> None/null
# TGDL: {"type":"Map/List/Integer", "value":"{}/[]/1"
# 如果结果集里没有value值或者值的数据类型不为列表则按照列表模板进行更新
if res["type"] == "Nothing" or res["type"] != "List":
res.update(list_template.copy())
else:
# 如果结果集里没有value值或者值的数据类型不为字典则按照map模板进行更新
if "value" not in res or type(res["value"]) is not dict:
res.update(map_template.copy())
#当pop后的路径的长度为0时,如果res的值为列表,则加到value里面,否则直接赋值给curr_path
if len(path) == 0:
if type(res["value"]) is list:
res["value"].append(argument)
else:
res["value"][curr_path] = argument
#再对路径更深层级里面的值进行递归
else:
#如果值的类型为列表时,则用append加到该列表里去,再递归调用该方法
if type(res["value"]) is list:
if len(res["value"]) < curr_path + 1:
res["value"].append({})
await construct_result(path, argument, res["value"][-1])
#如果当前路径里没有值时,则将其初始化,再递归调用该方法
else:
if curr_path not in res["value"]:
res["value"][curr_path] = {}
await construct_result(path, argument, res["value"][curr_path])
```
- 5. 路径递归算法逻辑
```Python
#路径递归算法
async def get_available_keys(obj: Union[Dict[str, Any], List]) -> List[str]:
# 如果对象为空或者对象里的type为Nothing,则返回空
if not obj or obj.get("type", None) == "Nothing":
return []
async def check_primitive(curr_obj: Dict[str, Any]) -> bool:
# 如果value不是一个字典,那么就代表不用递归下去了
obj_type = type(curr_obj.get("value", None))
# 返回对象类型为不是字典也不是列表
return obj_type is not dict and obj_type is not list
async def get_available_keys_helper(curr_obj: Dict[str, Any], result: set = set(), path: str = "") -> MutableSet:
# Base case: 当遇到Primitive就跳过
is_primitive = await check_primitive(curr_obj)
if is_primitive:
return set([path])
# 如果不是 primitive 那就继续检查
# 如果是一个map对象,则遍历它的键,递归返回path/key格式的路径,如:"data/Var1"
if curr_obj["type"] == "Map":
for key in curr_obj["value"]:
next_obj = curr_obj["value"][key]
if path:
new_path = "{}/{}".format(path, key)
else:
new_path = key
result = result.union(await get_available_keys_helper(next_obj, result.copy(), new_path))
# 如果是一个列表,则用enumerate组合为一个索引序列,遍历它的键,递归返回path/i 格式的路径,如:["Code", "Message", "Data/Var1", "Data/Var2"]中的"Data/Var2"
elif curr_obj["type"] == "List":
for i, next_obj in enumerate(curr_obj["value"]):
if path:
new_path = "{}/{}:int".format(path, i)
else:
new_path = path
result = result.union(await get_available_keys_helper(next_obj, result.copy(), new_path))
return result
#调用这个方法,用列表类型返回
keys = await get_available_keys_helper(obj)
return list(keys)
```
- 6.模板智能匹配的相似度阈值选取
```python
async def guess_service_mapping(from_nodes: List[mapping_query.QueryNode], to_node: mapping_query.QueryNode) -> Dict[str, Any]:
# 获取所有可以用的键
available_sources = {}
# 遍历结点,返回入参和出参的路径
for node in from_nodes:
if node.properties.arguments is not None:
keys = await get_available_keys(node.properties.arguments)
for key in keys:
available_sources[key] = {"type": "Argument", "id": node.id}
if node.properties.results is not None:
keys = await get_available_keys(node.properties.results)
for key in keys:
available_sources[key] = {"type": "Result", "id": node.id}
# 需要的键
required_keys = await get_available_keys(to_node.properties.arguments)
# 拼接参数
argument = {}
# resquired_keys 就是一连串的 路径, 比如 ["Code", "Message","Data/Var1", "Data/Var1"]
# required_key 就是一个路径,比如 "Data/Var1"
for required_key in required_keys:
#调用difflib包,其作用是比对文本之间的差异,返回一个分数列表
scores = [
(difflib.SequenceMatcher(None, required_key.split("/")[-1].lower(),
available_source.split("/")[-1].lower()).quick_ratio(), available_source)
for available_source in available_sources]
#类型默认的模板
template = {"type": "Nothing"}
if len(scores) > 0:
# 阈值 取中位数的1.3倍
threshold = max(0.5, statistics.median(map(lambda x: x[0], scores)) * 1.3)
# 筛选出大于阈值的分数,返回一个列表
filtered_scores = list(filter(lambda x: x[0] > threshold, scores))
if len(filtered_scores) > 0:
best = max(scores, key=lambda x: x[0])[1]
source = available_sources[best]
if source["type"] == "Result":
template = result_template
else:
template = argument_template
template["value"]["serviceNodeId"] = source["id"]
template["value"]["serviceKeyName"] = best
path = re.split(r"[/.]", required_key)
argument[required_key] = copy.deepcopy(template)
# 根据这个路径,去更新to_node.properties.arguments里面的内容
await construct_result(path, argument[required_key], to_node.properties.arguments)
return to_node.properties.arguments
```
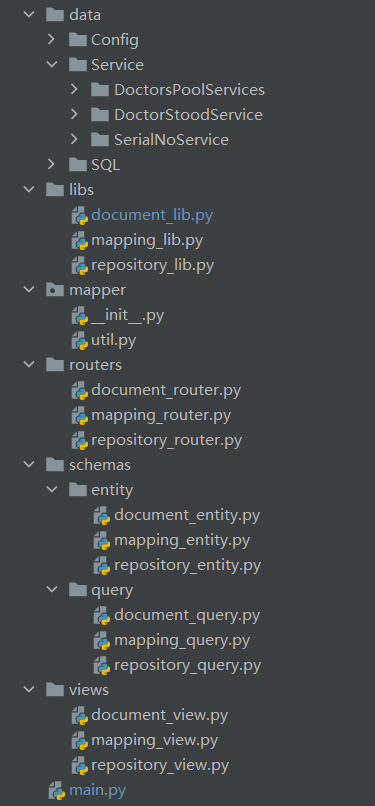
## (七)、部分文件结构