vue代码生成原理
# 前端代码生成原理及难点分析
## 一、代码生成原理
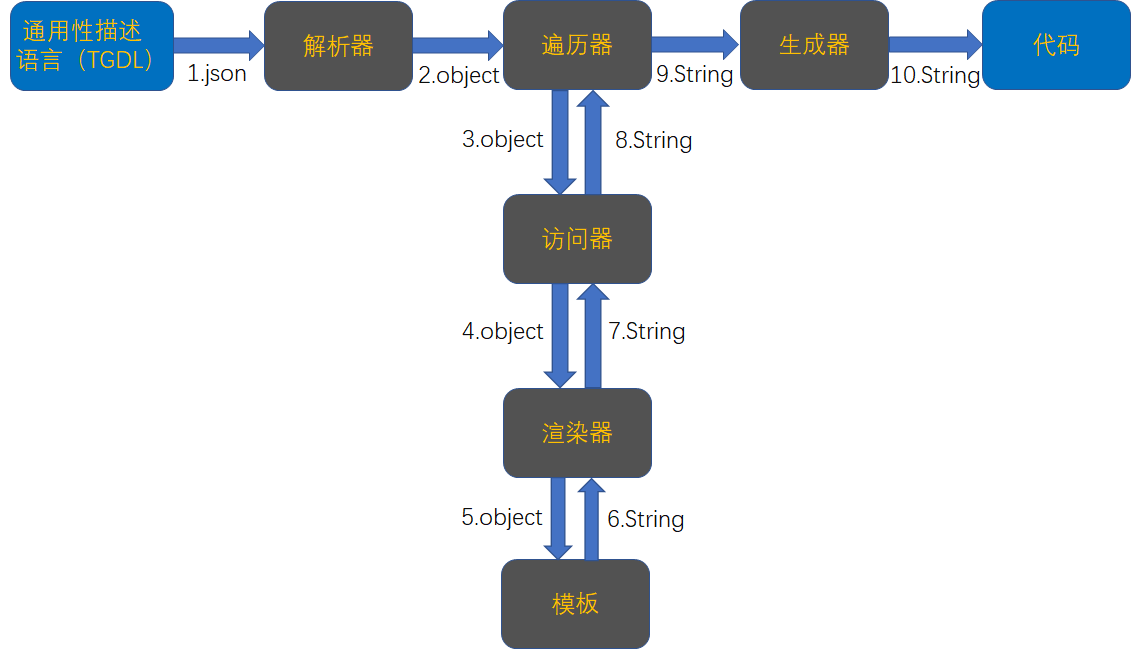
## 二、数据结构: 图 vs 树?
#### 后端程序结构是“图”结构(Graph)、而前端程序的结构是“树”结构(Tree)
- 生成后端代码时,最开始遍历器拿到的只是单个“入口”节点的数据,如果要生成其它的代码,遍历器需要自己去搜索到与当前节点相接的其它节点并访问它们。这样的搜索算法其实是很复杂的,不仅开发难,而且维护难。
- 而在生成前端代码时,我们拿到的是整个对象树的“根结点”,我们要做的仅仅是使用“DFS”算法不断递归深入访问这个树结构里的每一个“子节点”,并生成相应代码就可以了,因此前端的遍历算法与后端代码相比更容易。
- 从数据上来说,“AST”(抽象语法树)遍历器的代码量,是“流程图”遍历器代码量的三分之一,开发难度上也是差不多这个比例。
## 三、下一代Undo引擎:基于Diff算法的高效数据处理。
在开发工具中,很常见的需求是“前进”与“后退”。然后,目前常用的解决方案“快照”却有着很大的性能问题:他的原理是在每一次改动发生时,都将整体数据保存副本。一旦我们需要记录的数据较大,那么很快历史数据就会占用大量的空间。我们现在开发的是一个IDE,我们不仅要关注时间复杂度,也需要关注工具的空间复杂度。
除了快照以外,常用的解决方案就是基于“命令”的回滚。这种方案将每一种操作都写成了一种“命令”,再对每一种组件写一个“逆操作”的命令。比如我们写一个“新增组件”的命令,这个命令就要写一个相应的“删除组件”的命令。将这些命令记录下来,就可以实现开发过程中的前进与后退。然后,这种方案的缺点也很明显:大大加大的开发的复杂度,任何一个新的方法,我们都要开发一个相应的逆操作方法,这样相当于将开发的整体工作量x2。对我们来说,这样也是一个可以接受的方案,但是成本太高了。
最终,我们选择的是一个具有创新意义的方案:使用了一种基于LCS算法的Diff算法,实现了类似Git版本管理的增量Undo引擎。以下是我们的的性能分析结果:
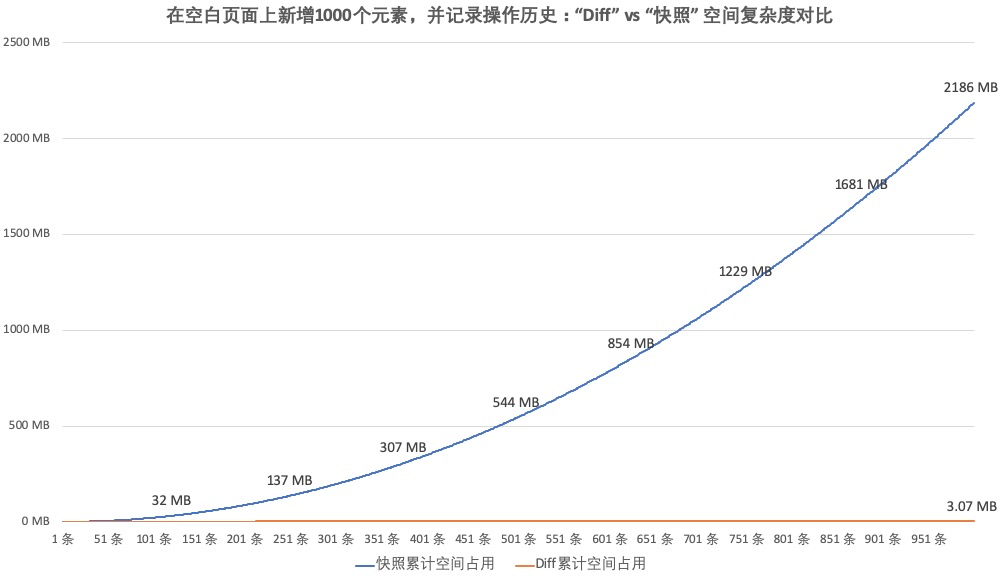
可以看出,我们的方案在极端情况下,空间占用比常用的快照方案少了近1000倍,但是,Diff算法显然是会带来额外的计算时间的。LCS算法理论上是O(nlogn)的时间复杂度,而快照在这个部分是0。看起来似乎有很大的区别,不过,我们还是来看看实际的测试数据。
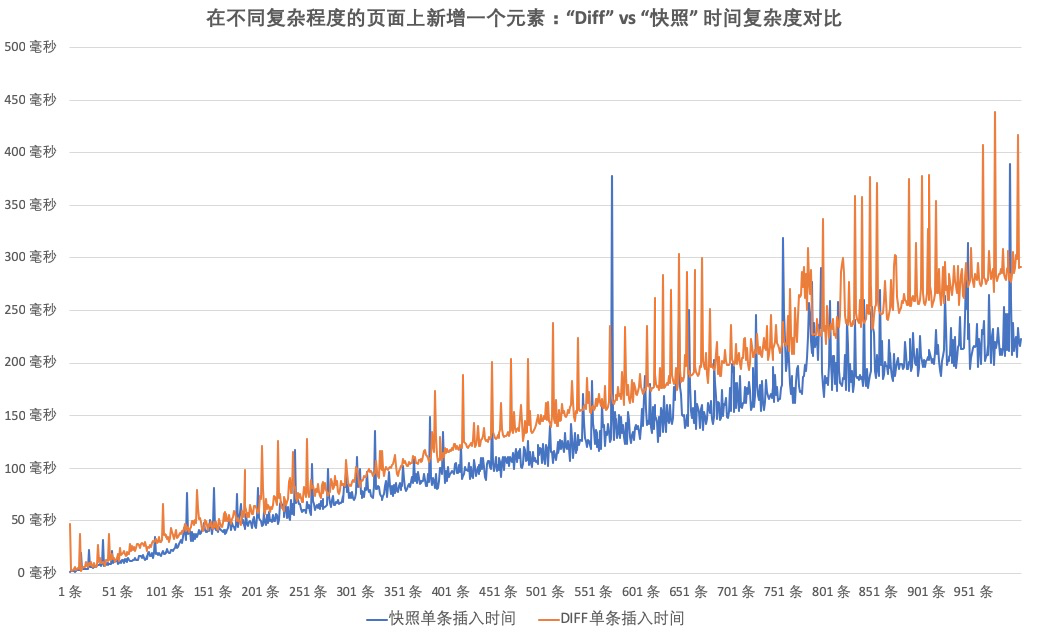
从以上结果可以看出,Diff确实增加了额外的时间复杂度,但是并没有我们想的那么大。在一个页面中插入超过900条元素后,我们发现,Diff算法下一条数据插入时间,与快照的数据插入时间相比,也只慢了不到100毫秒。这主要来源于两个原因:1、我们使用的LCS算法基于谷歌的一个开源项目,算法本身经过了很多性能优化。2、对900条数据的页面进行O(nlogn)复杂度的数据处理,在现代计算机的强大处理性能面前,依旧是一个相对简单的工作。
## 四、对模板引擎的挑战: 如何支持动态扩展?
#### 将模板写进数据库
- 之前我们的模板都是写死在项目中的,这样的问题就是:如果我要扩展一个新的基础组件,我就得改编译器的代码,并重新发布。
- 如何构建一个足够灵活的编译器架构,可以支持从数据库里动态的获取代码模版,并根据客户端传输的相关参数,正确高效的生成代码,成了我们要解决的核心问题。
- 如果模版是动态的,那么代码生成的时候,参数如何可靠的校验?错误时如何准确的报错?基础组件的属性面板应该如何配置?这些都需要我们给出答案。