JAVA基础02
## java JVM
### java 如何制造OOM
> 猜想这个是想要问人对oom了解情况的面试题
>
> 把问题进行拆分
> 1.什么是oom
> Out Of Menmory 英文全称 汉语内存溢出
> 两种情况会导致oom
> 内存泄露:内存使用过后没有进行销毁,造成这种情况
> 内存溢出:jvm分配的内存无法满足内存的需求就会造成内存溢出.
> 2.如何手动造成oom
> 1.写一个循环引用,然后不进行销毁
> 2.写一个特别大的对象,然后把jvm的大小设置的特别小
---
### 介绍JVM
> JVM的基本概念
>
> 感觉主要考察的点在于平台无关性和JVM的主要组成部分
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。 JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。JVM在执行字节码时,实际上最终还是把字节码解释成具体平台上的机器指令执行。
Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言使用Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。这就是Java的能够“一次编译,到处运行”的原因。
---
### Java 对象结构
> [对象结构](https://www.cnblogs.com/maxigang/p/9040088.html)
>
> java对象有两种(一定是8的倍数)
>
> 1. 普通对象 markword开头(8位) ,class地址(4位),实例数据
> 2. 数组对象 markword开头(8位),class地址(4位),长度(四位),实例数据
```
对象主要分为普通对象和数组对象
1.普通对象
1)对象头 8位 markword
用于存储对象自身的运行中数据,如:哈希码、GC分代年龄、锁状态标志、线程持有的锁,压缩是32位,不压缩是64位
存储对象的类型指针,通过这个指针可以来确定这个对象是哪个类的实例
数组的长度:如果对象是一个数组,那在对象头中还必须有一块数据用户记录数组的长度
2)对应的class的地址(指针) 4位
3)实例数据 :
a. 基本类型
b. 引用类型
实例数据是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容
4)对齐数据:padding 把对象补齐为8的倍数
此部分,并不是必然存在的,也没有特别的含义,它仅仅起着点位符的作用
2.数组对象
1)对象头 8位 markword
2)对应的class的地址 4位
3)输出长度:4字节
4)实例数据 :
a. 基本类型
b. 引用类型
5)对齐数据:padding 把对象补齐为8的倍数
```
---
### Java 内存模型(JMM)
> java内存模型:方法区,本地方法桟,堆,虚拟机桟,程序计数器,直接内存
>
> GC主要是回收方法区和,堆的相关信息
>
> 1. 方法区:又叫元数据区,存储主要是class和静态变量,常量,编译后的代码等
> 1. class是类加载器加载进来的class信息,包括类及其方法实现
> 2. 本地方法桟:主要存储的是native方法的 一般是调用C编写的
> 3. 堆:主要是对象存储的内存:如果是物理分区的新老堆的话,年轻代和老年代比例是1:2,年轻代中eden区,s1和s2三个区域的比例是8:1:1
> 4. 虚拟机桟:桟中主要存储的是桟帧,桟帧中包含:
> 1. 局部变量区: 定义变量名称 常量类型和对象类型
> 2. 操作数栈 : 处理逻辑
> 3. 动态链接 : 调用其它方法
> 4. 方法出口 : return
> 5. 程序计数器:它的作用是当前线程所执行的字节码的行号指示器
> 6. 直接内存:直接内存并不是虚拟机内存的一部分,也不是Java虚拟机规范中定义的内存区域。jdk1.4中新加入的NIO,引入了通道与缓冲区的IO方式,它可以调用Native方法直接分配堆外内存,这个堆外内存就是本机内存,不会影响到堆内存的大小.
链接:[JVM之虚拟机栈详解](https://juejin.cn/post/6844903983400632327)
---
### 重排序细节
> 可以详细的说一下MESI
>
> [连接:MESI详解](https://www.cnblogs.com/yanlong300/p/8986041.html)
>
>
>
> 1. 有两种重排:编译时指令重排,运行时指令重排
> 2. 原因
> 1. 编译重排因为java->class的时候会进行拆分
> 2. 运行时重排的原因是,内存速度远远小于cpu的缓存区,因此为了cpu利用率更高进行了指令重排
> 3. 禁止指令重排序
> 1. 当第一个操作为volatile变量的读时,在它之后的任何操作都不能被重排序到volatile读的前面
> 2. 当第二个操作为volatile变量的写时,在它之前的任何操作都不能被重排序到volatile写的后面
> 3. 当第一个操作为volatile写,第二个操作为volatile读时,不能重排序
---
### 强引用 软引用 弱引用 虚引用
>强引用 软引用 弱引用 虚引用
>
>1.对象引用 java有强软弱虚四种引用
>1)强引用普通的new对象就是强引用
>2)软引用
>如果堆内存不够使用的时候就会回收软引用(当做缓存用)
>3)弱引用
>当垃圾回收发现这个引用是个弱引用的时候就会直接进行回收,一般在容器中使用
>作用是当一个强引用指向了这里,当这个强引用消失的时候,弱引用就会消失
>比如ThreadLocal,是一个keyValue,key是弱引用,value是强引用,使用完后要remove掉
>4)虚引用 主要是给写jvm的人使用的 或者netty的时候
>虚引用如果进行碰到垃圾回收的时候一定会进行回收,并且会把结果放到一个队列里面,
>堆外内存使用的时候可以使用到,当检测到队列里有需要回收的对外内存的垃圾的时候,就进行堆外内存的回收
```
1.对象引用 java有强软弱虚四种引用
1)强引用普通的new对象就是强引用
2)软引用SoftReference<byte[]> m = new SoftReference<>(new byte[1024*1024*10]);
如果堆内存不够使用的时候就会回收软引用(当做缓存用)
3)弱引用WeakReference
WeakReference<M> m = new WeakReference<>(new M());
当垃圾回收发现这个引用是个弱引用的时候就会直接进行回收,一般在容器中使用
作用是当一个强引用指向了这里,当这个强引用消失的时候,弱引用就会消失
4)虚引用 主要是给写jvm的人使用的 或者netty的时候
虚引用如果进行碰到垃圾回收的时候一定会进行回收,并且会把结果放到一个队列里面,
堆外内存使用的时候可以使用到,当检测到队列里有需要回收的对外内存的垃圾的时候,就进行堆外内存的回收
private static final ReferenceQueue<M> QUEUE = new ReferenceQueue<>();
PhantomReference<M> m = new PhantomReference(new (M(),QUEUE);
```
---
### 内存结构,那些是线程私有的,那些是共有的
> [内存结构,那些是线程私有的,那些是共有的](https://blog.csdn.net/qiezikuaichuan/article/details/105086614)
>
> JVM内存模型可以分为两个部分,堆和方法区是所有线程共有的,而虚拟机栈,本地方法栈和程序计数器则是线程私有的。
---
### 内存模型、CPU有这套架构,为什么JVM实现一遍
> 因为java是跨平台的语言,为了平台无关性.
---
### java bean的生命周期 双亲委派
>[类加载、双亲委派,参考文档](https://www.cnblogs.com/xdouby/p/5829423.html)
> java的bean的加载机制(类加载是采用双亲委派机制)
>
> 1. 装载(Load) 查找并加载类的二进制数据
> 2. 连接(Link)
> 1. 验证 : 确保被加载类的正确性(验证文件是否符合jvm规定) 如:是否是以cafebe开关的
> 2. 准备: 为类的静态变量分配内存,并将其初始化为默认值
> 3. 解析: 把类中的符号引用转换为直接引用
> 3. 初始化(Initialize) 为类的静态变量赋值
>
>
>
> 双亲委派
>
> [连接:双亲委派](https://www.jianshu.com/p/9df9d318e838)
>
> 1. 双亲其实就是一个从父到子的过程,一个是从子到父的过程
>
> 2. 目的是为了安全,如果没有这个机制 如:随便给一个java.lang.string 把jvm的覆盖,把自己的内容搞进行,比如客户输入一个密码直接发邮件到自己的邮箱,导致不安全问题产生,还有就是如果没有这个机制加载多次有资源浪费的情况
>
> 3. 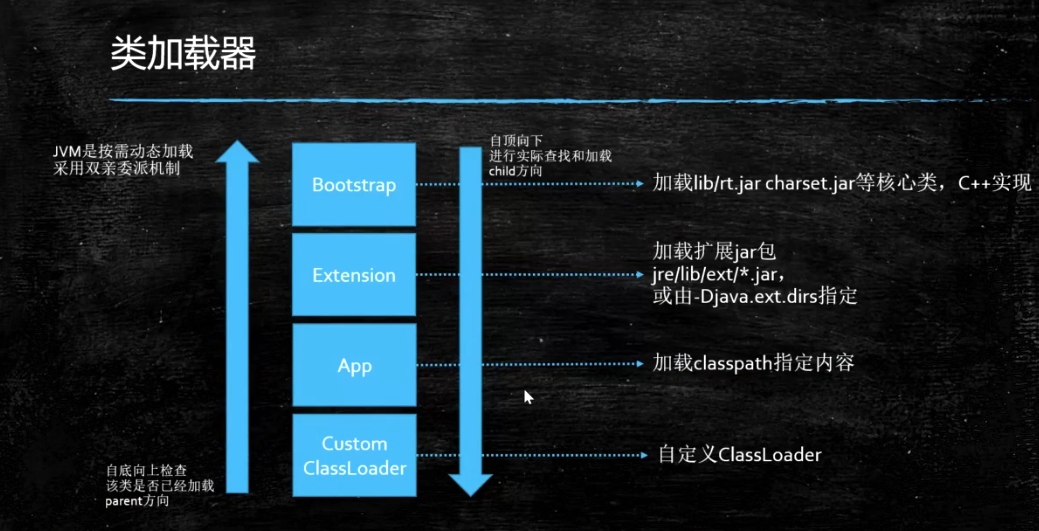
>
>
---
### 描述java虚拟机的内存模型
> [描述java虚拟机的内存模型](https://www.cnblogs.com/swordfall/p/10723938.html)
>
> [java虚拟机的内存模型](https://blog.csdn.net/weixin_37817685/article/details/89071055)
>
> java内存模型:方法区,本地方法桟,堆,虚拟机桟,程序计数器,直接内存
>
> 1. 方法区:又叫元数据区,存储主要是class和静态变量,常量,编译后的代码等
> 2. 本地方法桟:主要存储的是native方法的
> 3. 堆:主要是对象存储的内存:如果是物理分区的新老堆的话,年轻代和老年代比例是1:2,年轻代中edun区,s1和s2三个区域的比例是8:1:1
> 4. 虚拟机桟:桟中主要存储的是桟帧,桟帧中包含:
> 1. 局部变量区
> 2. 操作数栈
> 3. 动态链接
> 4. 方法出口
> 5. 程序计数器:它的作用是当前线程所执行的字节码的行号指示器
> 6. 直接内存:直接内存并不是虚拟机内存的一部分,也不是Java虚拟机规范中定义的内存区域。jdk1.4中新加入的NIO,引入了通道与缓冲区的IO方式,它可以调用Native方法直接分配堆外内存,这个堆外内存就是本机内存,不会影响到堆内存的大小.
---
### java 垃圾标记算法
> GC两种标记算法
>
> 1. 引用计数法:引用计数算法就是在对象中添加了一个引用计数器,当有地方引用这个对象时,引用计数器的值就加1,当引用失效的时候,引用计数器的值就减1。
> 2. 根可达算法:GC Roots对象一般包括有:1.虚拟机栈(栈帧中本地变量表)中引用的对象;2.方法区中类静态属性引用的对象;3.方法区中常量引用的对象;4.本地方法栈中JNI(Native方法)引用的对象
1.引用计数法
引用计数算法就是在对象中添加了一个引用计数器,当有地方引用这个对象时,引用计数器的值就加1,当引用失效的时候,引用计数器的值就减1。当引用计数器的值为0时,jvm就开始回收这个对象。
简单的来说,在JVM中的栈中,如果栈帧中指向了一个对象,那么堆中的引用计数器的值就会加1,当栈帧这个指向null时,对象的引用计数器就减1。
这种方法虽然很简单、高效,但是JVM一般不会选择这个方法,因为这个方法会出现一个问题:当对象之间相互指向时,两个对象的引用计数器的值都会加1,而由于两个对象时相互指向,所以引用不会失效,这样JVM就无法回收。
2.根可达算法
GC Roots对象一般包括有:1.虚拟机栈(栈帧中本地变量表)中引用的对象;2.方法区中类静态属性引用的对象;3.方法区中常量引用的对象;4.本地方法栈中JNI(Native方法)引用的对象
---
### java 垃圾回收算法
[垃圾回收算法学习连接](https://blog.csdn.net/yrwan95/article/details/82829186)
>1. 标记清除(mark sweep):找到所有的垃圾标记,然后进行清除.分为标记阶段和清除阶段
> 1. 缺点:内存位置不连续、容易产品碎片、如果有大对象放不下容易产生FGC;效率偏低;适合存活对象比较多.扫描次数为两次
>2. 拷贝(复制)算法(copying):把内存一份为二,找到所有的垃圾标记,然后把有用的对象复制到领一边,
> 1. 缺点,需要给对象做复制移动,因为移动了因此引用也变了,需要整理对象引用,浪费空间,只需要扫描一次
> 2. 没有碎片,但是浪费空间
>3. 标记压缩(mark compact):把存活对象移动到空间的一端,然后把其他空间的对象进行清除
> 1. 缺点:需要扫描两次,也需要进行复制和移动,优点没有额外的空间,并且内存空间比较连续
> 2. 没有碎片,效率偏低
```
垃圾回收的方法:
1)标记清除:找到所有的垃圾标记,然后进行清除.缺点:内存不连续,适合存活对象比较多.扫描次数为两次
2)标记拷贝:把内存一份为二,找到所有的垃圾标记,然后把有用的对象复制到领一边,缺点,需要给对象做复制移动,因为移动了因此引用也变了,需要整理对象引用,浪费空间,只需要扫描一次
3)标记整理:把存活对象整理到空间的一端,然后把其他空间的对象进行清除,缺点:需要扫描两次,也需要进行复制和移动,优点没有额外的空间,并且内存空间比较连续
3.垃圾的逻辑分区
1)除了ZGC Shenandoah之外的GC都是使用逻辑分代模型,其中G1是逻辑分代,其他的不仅仅是逻辑分代,而且是物理分代
2)堆内的逻辑分区
a.一个Eden区:刚刚被new的对象如果Eden能放下,就会放到Eden区域
b.二个survivor区域:当对象经历了一次垃圾回收的时候,如果仍然存活,能放到survivor中就会在两个survivor区域中切换
c.old区:如果对象上来就比较大,就会直接进入tenurd区域,或者当年龄很老的时候会进入tenurd区域,这个年龄大上限是15,因为对象的markword中年龄的标识只有4位
3)新生成的对象的分配逻辑
a.桟上分配(如果对象只有线程私有,很小,支持标量替换,无逃逸)
b.线程本地分配TLAB,eden会给每一个线程划出一个线程私有的空间,目的是为了减少征用,提高效率
c.old区域,当对象比较大,在eden区域放不下的时候会直接给他放到老年代区域
d.放到eden区域
```
---
### 有哪些垃圾回收算法,垃圾回收器G1,G2的区别
[常用的垃圾回收器-参考](https://blog.51cto.com/10983206/2550682)
> 垃圾回介绍:
>
> 1. 新生代垃圾回收器
>
> 1. Serial 它是一种单线程垃圾回收器,历史最久的,jdk1.3.1之前的唯一选择也是默认的垃圾回收器
> 1. 优点:简单高效,拥有很高的单线程搜集效率
> 2. 缺点:收集过程需要暂停所以的线程
> 3. 算法:复制算法(copying)
> 2. ParNew Serial垃圾回收器的多线程版本
> 1. 优点:在多个cup时,比Serial效率高
> 2. 缺点:收集过程暂停所有应用程序线程,单cup时比Serial效率差
> 3. 算法:复制算法(copying)
> 3. Parallel Scanvenge
> 1. Parallel Scanvenge 看上去和PawNew一样,但是Parallel Scanvenge更关注系统的吞吐量
> 2. 算法:复制算法
> 3. 是一个新生代收集器,目的是达到一个可控制的吞吐量,它提供了两个参数用户精确的控制吞吐量
> 4. -XX:MaxGCPauseMillis控制最大的垃圾收集停顿时间
> -XX:GC Time Ratio直接设置吞吐量的大小
>
> 2. 老年代垃圾回收器
>
> 1. CMS Concurrent Mark Sweep
>
> 1. 特点:最短回收停顿时间
> 2. 算法:标记-清除
> 3. 回收步骤:
> 1. 初使标记:标记 GC Roots 直接关联的对象,速度快
> 2. 并发标记:GC Roots Tracing 过程,耗时长,与用户进程并发工作
> 3. 重新标记:修正并发标记期间用户进程运行而产生变化的标记,耗时比初使标记时间长,但是远远小于并发标记
> 4. 并发清除:清除标记的对象
> 4. 缺点:无法回收浮动垃圾、采用标记清除算法会产生内存碎片
>
> 2. Serial Old -- Serial Old收集器是Serial收集器的老年代版本,也是一个单线程收集器
>
> 1. 算法:标记压缩(整理)算法
> 2. 运行过程和Serial一样
> 3. 优点:
> 1. CMS收集器后备预案,在并发收集发生Concurrent Mode Failure时使用
> 4. 缺点:单线程
> 5. Parallel old : Parallel Old收集器是Parallel Scavenge收集器的老年代版本
> 1. 算法:标记-整理(清除)
> 2. 为了替代`serial old`与`Parallel Scanvenge`配合使用。
>
> 3. 上边新上代和老年代垃圾回收器总结
>
> 1. jdk 1.7、1.8 使用的垃圾回收器是 ps(新生代) + po(老年代)
>
> 2. ps : Parallel Scanvenge ; po:Parallel Old
>
> 3. jdk 1.9 使用的是G1
>
> 4. **-XX:+PrintCommandLineFlagsjvm参数可查看默认设置收集器类型**
>
> **-XX:+PrintGCDetails亦可通过打印的GC日志的新生代、老年代名称判断**
>
> 查看方法:java -XX:+PrintFlagsInitial|grep UseConcMarkSweepGC
>
> 4. G1--->Garbage first 逻辑分代,物理不分代 上边的垃圾回收器都是逻辑分代、物理也分代
>
> 1. 作用年代:新生代/老年代
> 2. G1 是一个具备所有 GC 特性的垃圾回收器,因此将 G1 设置为 JVM 默认的 GC。
> 3. 为了减轻 GC 代码的维护负担以及加速新功能开发,决定在 JDK 9 中废弃 CMS GC
> 4. G1将整个`JVM`堆划分成多个大小相等的独立区域`regin`,跟踪各个`regin`里面的垃圾堆积的价值大小,在后台维护一个优先列表,每次根据允许的收集时间,优先回收最大的`regin`,当然还保留有新生代和老年代的概念,但新生代和老年代不在是物理隔离了,他们都是一部分`regin`集合。
> 5. **回收步骤**:
> 1. 初始标记:标记`GC Roots`直接关联的对象
> 2. 并发标记:对堆中对象进行可达性分析,找出存活对象,耗时长,与用户进程并发工作
> 3. 最终标记:修正并发标记期间用户进程继续运行而产生变化的标记
> 4. 筛选回收:对各个`regin`的回收价值进行排序,然后根据期望的`GC`停顿时间制定回收计划
>
> 5. ZGC 在`JDK 11`新加入,还在实验阶段,逻辑不分代、物理也不分代
>
>
```
1. 线程私有的:
1)程序计数器:记录指令执行
2)本地方法桟:native方法的地方
3)虚拟机桟:里面存放着桟针
<1>桟针:一个方法是一个桟针
a. 局部变量表
b. 操作数桟
c. 引用关联表
d. 返回对象
2.线程共有有的:
1) 堆Heap:存放着对象内容
2) 方法区:1.8之前是放在在jvm维护的区域中
1.8之后维护在直接内存(非运行时数据区)中
二. 垃圾回收
1.垃圾定位的方法:
1)引用计数法:在对象上加上引用的计数,每减少一次引用就会进行减一(缺点如果两个对象相互引用就不能定位了)
2)根可达算法:
<1> 哪些是跟的引用:
a.线程站中的桟针中的引用
b.静态变量
c.常量池
d.本地方法的对象
e.clazz
2.垃圾回收的方法:
1)标记清除:找到所有的垃圾标记,然后进行清除.缺点:内存不连续,适合存活对象比较多.扫描次数为两次
2)标记拷贝:把内存一份为二,找到所有的垃圾标记,然后把有用的对象复制到领一边,缺点,需要给对象做复制移动,因为移动了因此引用也变了,需要整理对象引用,浪费空间,只需要扫描一次
3)标记整理:把存活对象整理到空间的一端,然后把其他空间的对象进行清除,缺点:需要扫描两次,也需要进行复制和移动,优点没有额外的空间,并且内存空间比较连续
3.垃圾的逻辑分区
1)除了ZGC Shenandoah之外的GC都是使用逻辑分代模型,其中G1是逻辑分代,其他的不仅仅是逻辑分代,而且是物理分代
2)堆内的逻辑分区
a.一个Eden区:刚刚被new的对象如果Eden能放下,就会放到Eden区域
b.二个survivor区域:当对象经历了一次垃圾回收的时候,如果仍然存活,能放到survivor中就会在两个survivor区域中切换
c.tenurd:如果对象上来就比较大,就会直接进入tenurd区域,或者当年龄很老的时候会进入tenurd区域,这个年龄大上限是15,因为对象的markword中年龄的标识只有4位
3)新生成的对象的分配逻辑
a.桟上分配(如果对象只有线程私有,很小,支持标量替换,无逃逸)
b.线程本地分配TLAB,eden会给每一个线程划出一个线程私有的空间,目的是为了减少征用,提高效率
c.old区域,当对象比较大,在eden区域放不下的时候会直接给他放到老年代区域
d.放到eden区域
三.常见的垃圾回收器
0. serial --> serial Old
parallel Scavenge -->PO 默认的垃圾回收方法
ParNew -->CMS
1. serial:特点单线程进行垃圾回收,在一个安全的时间(safe point) 进行STW(stop the world) 进行垃圾回收(回收方式用的是标记复制) (年轻代)
2. serial Old :单线程在老年代进行垃圾回收 ,用的是标记清理或者标记整理来进行回收
3. parallel Scavenge :多线程清理垃圾,用的是标记复制算法
4. parallel old :多线程清理垃圾,用的是标记整理算法
5. ParNew : 相当于parallel Scavenge的增强 ,为了配合cms,在cms的特定的时间点parNew也会一起进行,采用的也是标记复制算法
6. CMS:他的诞生大大减少了STW的时间,它开启了并发回收,目前JDK的版本默认都不是.
初始标记(STW)->并发标记->重新标记(STW)->并发清理(会有一些浮动垃圾等下一次清理)
CMS的缺点:1)内存的碎片化:当碎片化到一定程度的时候他会使用serialold方法进行清理,这样单线程进行清理大内存的情况就会很久
2)浮动垃圾:如果浮动垃圾没有清理完,而old区域满了,就会叫出来serialold进行清理
如何避免这些事情:1.减低CMS触发serialOld的阈值
2.给更大的老年代的空间
3.定时重启服务
```
---
### JVM GC时间长如何发现、后来改成问成接口慢如何排查原因
> [GC优化](https://blog.csdn.net/weixin_39639119/article/details/88830930)
>
> 系统CPU经常100%,如何调优?
>
> CPU100%那么一定有线程在占用系统资源
>
> 1. 找出哪个进程cpu高(top)
> 2. 该进程中的哪个线程cpu高(top -Hp)
> 3. 导出该线程的堆栈 (jstack)
> 4. 查找哪个方法(栈帧)消耗时间 (jstack)
> 5. 工作线程占比高 | 垃圾回收线程占比高
>
>
---
### 有没有JVM调优的经验、如何JVM 调优,Dump 日志如何分析
> 1. 多线程进行批扣,扣款直接在for 循环中new 对象和在for中查询数据库
>
> 1. 运维团队收到受到报警信息
>
> 2. top命令观察到问题:内存不断增长 CPU占用率居高不下
>
> 3. top -Hp 观察进程中的线程,哪个线程CPU和内存占比高
>
> 4. jps定位具体java进程
> jstack 定位线程状况,重点关注:WAITING BLOCKED
>
> 5. (插播)阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称
> 怎么样自定义线程池里的线程名称?(自定义ThreadFactory)
>
> 6. jmap -dump:format=b,file=xxx pid :
>
> 线上系统,内存特别大,jmap执行期间会对进程产生很大影响,甚至卡顿(电商不适合)
> 1:设定了参数HeapDump,OOM的时候会自动产生堆转储文件
> 2:<font color='red'>很多服务器备份(高可用),停掉这台服务器对其他服务器不影响</font>
> 3:在线定位(一般小点儿公司用不到)
>
> 7. 使用MAT / jhat /jvisualvm 进行dump文件分析
>
> 8. 找到代码的问题
>
> 1. 如使用jvisualvm进行分析的时候,可以对实例数进行排序,基本最多的就是有问题的代码
---
### 为什么要避免 FullGC
> [GC优化](https://blog.csdn.net/weixin_39639119/article/details/88830930)
>
> heap区被占满,需要回收heap空间, 就会执行fullGC
> 对象生命周期经历了young(eden, I , II )到达old
> fullGC是对old和young全部GC
> 此时JVM处于冻结状态
---
### 为什么采用三色标记清除?
> [三色标记算法参考](https://www.cnblogs.com/jmcui/p/14165601.html)
>
> 1. 我们把遍历对象图过程中遇到的对象,按“是否访问过”这个条件标记成以下三种颜色
> 1. 白色:尚未访问过
> 2. 灰色:本对象已访问过,但是本对象引用到的其他对象尚未全部访问完
> 3. 黑色:本对象已访问过,而且本对象引用到的其他对象也全部访问过了
>
> 2. 初始时,所有对象都在 【白色集合】中;
>
> 3. 将GC Roots 直接引用到的对象 挪到 【灰色集合】中;
> 4. 从灰色集合中获取对象:
> 3.1. 将本对象 引用到的 其他对象 全部挪到 【灰色集合】中;
> 3.2. 将本对象 挪到 【黑色集合】里面。
> 5. 重复步骤3,直至【灰色集合】为空时结束。
> 6. 结束后,仍在【白色集合】的对象即为GC Roots 不可达,可以进行回收。
---
### 什么是full gc,过程,触发的条件是什么
> full gc:
>
> 就是新生代和老年代一起进行gc的事件
>
> 触发条件
>
> 1. 老生代空间不够分配新的内存
> 2. System.gc(),见Minor GC触发条件的第2点。
> 3. 通过Minor GC后进入老年代的平均大小大于老年代的可用内存。
> 4. Minor GC时,eden space和from space区大小大于to space且大于老年代内存,触发Full GC。
> 5. Metaspace空间不足。
## JAVA 基础
### Hashmap实现
> [HashMap实现原理01](https://blog.csdn.net/vking_wang/article/details/14166593)
>
> [HashMap实现原理02](https://blog.csdn.net/zhengwangzw/article/details/104889549/)
>
> 1. 数据结构:哈希表=数组+链表(内部使用数组 + 链表红黑树)
> 1. 结合了数组寻址容易,插入和删除困难
> 2. 结合了链表寻址困难,插入和删除容易的特点
> 2. 首先HashMap里面实现一个静态内部类Entry,其重要的属性有 *key , value, next*
> 3. (n - 1) & hash == hash % n
> 4. hash函数是先拿到 key 的hashcode,是一个32位的int值,然后让hashcode的高16位和低16位进行异或操作。
> 5. ***\*扩容(resize)\****就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素
1. [参考链接][https://blog.csdn.net/aichuanwendang/article/details/53317351]
> 6. 为什么扩容加载因子是0.75,树化的时候链表长度是8,数组长度是64
默认加载系数(0.75)提供了一个很好的选择时间和空间成本的权衡。较高的数值会降低空间开销,但增加查找成本
因为达到8个元素的时候,概率已经很低了。此时树化,性价比会很高。
既不会因为链表太长(8)导致复杂度加大,也不会因为概率太高导致太多节点树化。
参考文章:https://blog.csdn.net/weixin_43883685/article/details/109809049
---
### 常见的集合以及实现原理
> 知道其他的map的原理
>
> [Map](https://blog.csdn.net/qq_40574571/article/details/97612100)
>
> 稍后补充
---
### 常见的queue
> [queue](https://www.cnblogs.com/lemon-flm/p/7877898.html)
>
> 稍后补充
---
### currenthashmap 原理
---
> [currenthashmap](https://blog.csdn.net/qq_22343483/article/details/98510619)
---
### 动态代理
> [java动态代理](https://www.cnblogs.com/gonjan-blog/p/6685611.html)
>
> 稍后补充
---
### 反射
> [反射](https://blog.csdn.net/lililuni/article/details/83449088)
>
> 稍后补充
## 设计模式
### 单例模式
---